What is fuzz testing?
Fuzz testing is a type of automated software testing; a method of discovering bugs in software by providing random input to the software under the test and monitoring any crashes and failed assertions. Fuzzer is a computer program that offers random inputs to the software. Fuzz testing can be applied to virtually any software program, including HTTP APIs.

Smart vs. dumb fuzzing
As mentioned earlier, a fuzzer provides random data to the software under the test. The input can be entirely random without matching the shape of the expected input or generated to match a valid input.
Dumb Fuzzer
Dumb fuzzers produce completely random input that does not necessarily match the shape of the expected input. Lack of built-in intelligence about the software it’s fuzzing makes this type of fuzzer a dumb one. Due to their simplicity, dumb fuzzers can produce results with little work. On the other hand, dumb fuzzers may be able to fuzz only certain areas of the software.
For example, the presence of the newsletter boolean field in the request payload of a Rest API endpoint for creating a new user triggers the logic for newsletter subscription. But, as you may have already guessed, a dumb fuzzer won’t be able to begin the execution of the newsletter subscription logic and identify potential bugs in that area of the code due to the wholly randomized input that does not match the valid input.
Pros & Cons of dumb fuzzing
| Dumb fuzzing pros | Dumb fuzzing cons |
|---|---|
| Straightforward to set up, run, and maintain | Limited code coverage due to the fully randomized input |
| Requires minimum amount of work for the initial setup | Sometimes, it tests a parser than your program |
Smart Fuzzer
Smart fuzzers push the boundaries of fuzz testing by generating randomized data valid enough to pass program parser checks, get deep into the program logic, and potentially trigger edge cases and find bugs.
The more built-in intelligence you add into your smart fuzzer, the greater code coverage you will have.
Pros & Cons of smart fuzzing
| Smart fuzzing pros | Smart fuzzing cons |
|---|---|
| Greater code coverage in comparison with dumb fuzzers | Requires more work to set up, run and maintain |
| Catches more bugs thanks to greater code coverage |
Fuzzer types
Based on the way a fuzzer generates the randomized input data, we can divide fuzzers into mutation-based and generation-based fuzzers.
Mutation-based fuzzers
A mutation-based fuzzer takes valid inputs and generates a collection of inputs by changing (mutating) the valid inputs.
Generation-based fuzzers
A generation-based fuzzer analyses the provided valid input structure and generates entirely new data that matches the valid one from the structure perspective.
Generating random data
Mutation-based and generation-based fuzzers both generate random data, albeit taking different approaches. The experience has proven that including specific values can trigger edge cases and bring bugs to the surface. The table below goes through some values proven to bring bugs to the surface.
| Value | Description |
|---|---|
| Empty strings | Sometimes, empty string by-pass missing value checks and trigger bugs |
| Long strings | Bugs as a result of truncation come to the surface as a result of passing long strings to programs |
| Strings with variant length | Short, medium, and long strings can trigger bugs as well |
| 0 | Similar to empty strings, value 0 can sometimes pass the missing value checks and trigger bugs |
| Negative numbers | Triggers bugs related to assuming positive numbers but lacking validation for that |
| Decimals | Triggers bugs related to assuming integers but lacking validation for that |
| Special characters | Bring up bugs related to embedding values in URL or saving in database |
| Max / Min numbers | Does the code cope well with a maximum allowed number? what about the minimum? |
Code coverage in fuzz testing
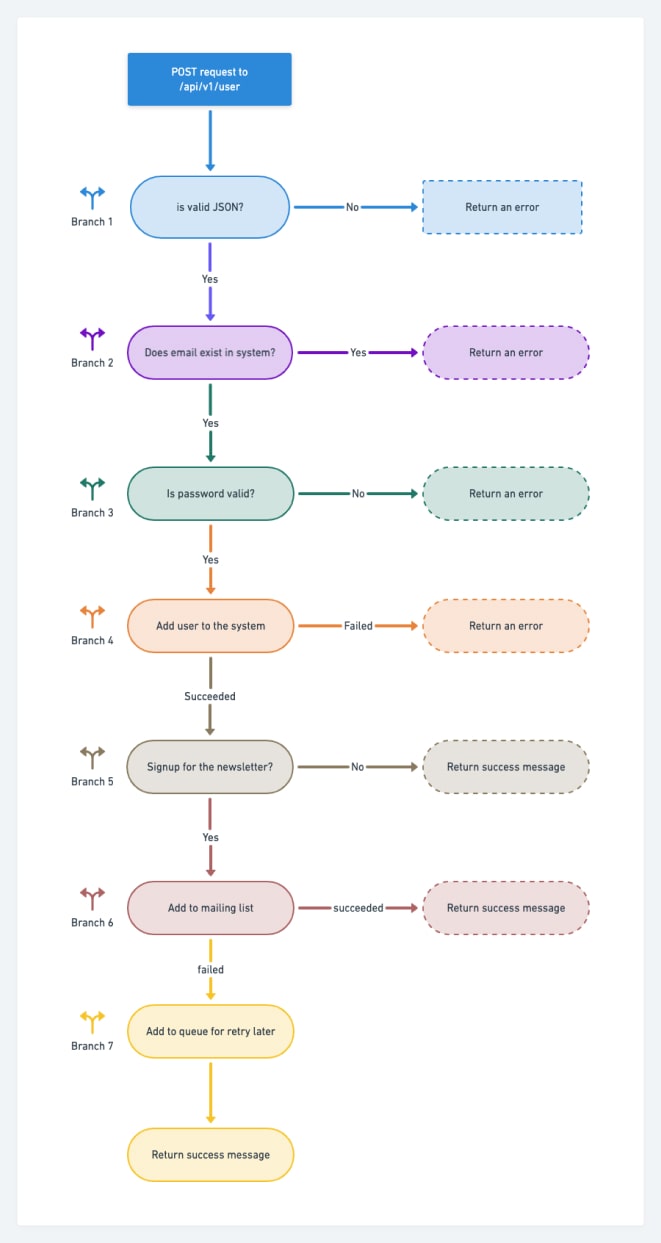
Code coverage refers to the percentage of the executed code while running the test cases against the source code. Broadly speaking, the greater the coverage percentage, the better it is. Therefore, while doing fuzz testing, you should always keep an eye on the part of the code you fuzz. For example, a dumb fuzzer can potentially fuzz the parser code than your business logic. Moreover, a mutation-based or generation-based fuzzer will trigger the execution of the code in different branches of the source code.
The diagram below shows seven branches of code that a fuzzer can trigger via input. But, of course, not every fuzzer can start all branches.
Why should you keep an eye on API Fuzzing?
When it comes to keeping our apps secure, we perform various kinds of testing methods such as static code analysis, dynamic code analysis, penetration, and more to protect them from the eyes of attackers. But usually, APIs are in the blind spot of the application security testing methods.
Unfortunately, in many software companies, security leaders think their APIs and products are safe because of performing regular penetration testing, not knowing the hackers find the software vulnerabilities through fuzzing. So, here is the fun fact, if you want not to be a victim of hackers, think like a hacker and find your software loopholes.
Consider the fuzzing practice in your penetration tactics and techniques for more accurate results about API vulnerabilities.
What are the taxonomies of API fuzzers?
Different companies have various approaches to finding vulnerabilities through fuzzing, but Microsoft’s taxonomies are generally more common and accepted.
Knowledge of Input
Some called them “smart fuzzers,” as we discussed previously in this article; they know the expected input format of the application. So, for example, they know that the input file should be in text format.
Knowledge of target application structure
There are also different categories for fuzzers I want you to hear: black-box, white-box, and gray-box fuzzers.
In the white-box approach, the tester or the test tool has all the required information of the input format and structure of the target, so there is no need to guess them in the opposite of the black-box testing approach.
So in the world of fuzzers, the white-box fuzzer who knows all about the target application, and the gray-box fuzzer who has partial knowledge of the target application, are the smartest fuzzers.
Method of generating new input
As discussed earlier in this article, fuzzers can randomly generate new input from scratch or change the pre-existed input to test the target with them.
API Fuzz Testing
API fuzz testing is a dynamic software testing technique that’s been gaining traction for its effectiveness in uncovering vulnerabilities in APIs. It works by sending unexpected or invalid input data to the APIs, often catching issues that other testing methods might miss. This type of testing is typically used in black-box testing scenarios to identify and prevent security flaws, ensuring APIs function as expected under various conditions.
Types of API Fuzzing
There are different approaches for API fuzzing, and each has unique advantages. Let’s have a look at each type of API fuzz testing:
Black-Box Fuzzing
Black-box fuzzing tests an API without any knowledge of its internal workings. Testers only have access to the public-facing endpoints and send unexpected input data to see how the API handles it. This approach mimics how an attacker would probe for vulnerabilities.
Grey-Box Fuzzing
Grey-box fuzzing involves testing an API with partial knowledge of its internal structure. Testers may have some access to documentation or parts of the code but still focus on providing unexpected input data to find weaknesses.
White-Box Fuzzing
A more detailed approach called “white-box fuzzing” gives testers complete access to the source code of the API. With this knowledge, they may produce advanced and customized input data, which improves testing efficiency and effectiveness.
Why API Fuzzing is Crucial
Imagine you have an API that handles user authentication. A malicious attacker might try to exploit it by sending extremely long usernames, passwords with special characters, or other unexpected data. API fuzzing helps prevent such attacks by rigorously testing the API with various kinds of unexpected input data, such as:
- Long strings of random characters
- Non-alphanumeric characters
- Special symbols
By using automated tools to run these tests, you can identify and fix vulnerabilities before attackers can exploit them.
Security Benefits of API Fuzzing
API fuzzing offers several security benefits:
- Identifying Vulnerabilities: It helps uncover issues that might be missed by other testing techniques. By sending unexpected data, it exposes weaknesses that attackers could exploit.
- Enhancing Security: By identifying and fixing these vulnerabilities, API fuzzing enhances the overall security of your application, helping to prevent data breaches and cyber-attacks.
- Preventing Cyber Attacks: Since APIs are common entry points for attackers, securing them through fuzz testing can save an organization from costly and damaging attacks.
The Role of Fuzz Testing in Overall Security
Hackers often use fuzzing to find vulnerabilities without needing access to the source code. They can then exploit these weaknesses through methods like DDoS attacks or SQL injection. Fuzz testing is particularly good at identifying zero-day vulnerabilities—those that attackers discover before the software vendor is aware of them. While fuzz testing is powerful, it’s not a silver bullet. Comprehensive security testing should also include penetration testing and static code analysis to ensure the highest level of security.
Practical Aspects of API Fuzz Testing
API fuzz testing typically involves generating and running test cases with invalid or random data to find any issues. Here is a closer look at how it works:
Test Case Generation
Either new data is created or existing data is modified to create test cases. In order to ensure a comprehensive analysis of the API, this can include boundary conditions, valid inputs, and invalid inputs.
Execution and Monitoring
The created test cases are executed against the API, and the system’s behavior is monitored for any unexpected outcomes, such as crashes or hangs. This helps identify issues that could lead to security vulnerabilities or instability.
Results Analysis and Bug Reporting
After executing the test cases, any identified issues are documented, including the input data and system behavior. This information helps developers investigate, debug, and resolve the problems.
Iterative Process
Fuzz testing is iterative, meaning it’s performed multiple times with different test cases to identify as many vulnerabilities as possible. Each iteration may refine test case generation techniques or adjust the testing focus based on previous results.
Automation
Fuzz testing can be automated to improve efficiency and reduce manual effort. Automated tools can handle test case generation, execution, monitoring, and result analysis.
Advantages of API Fuzz Testing
- Robustness: Helps find problems that conventional testing techniques might overlook, leading to a more reliable API.
- Security: Uncovers vulnerabilities that could be exploited by malicious actors, enhancing overall API security.
- Scalability: Automated fuzz testing can scale to test large and complex APIs, making it suitable for organizations with extensive API ecosystems.
- Comprehensive Testing: Covers a broad range of input values and scenarios, leading to more thorough API testing.
Limitations of API Fuzz Testing
- False Positives: It can generate many test cases, leading to false positives (finding bugs that aren’t there) or false negatives (missing real bugs).
- Limited Coverage: May fail to cover all scenarios or input values, which could result in certain problems going unnoticed.
- Time-Consuming: Depending on the API’s size and complexity, fuzz testing can be time-consuming, especially if done manually.
- Limited Effectiveness for Certain Bugs: For certain kinds of issues, including logic errors or memory leaks, it might not work well.
- Difficulty with Complex Systems: It may not be suitable for testing highly complex systems with many interdependent components.
Fuzz testing APIs using Testfully
Testfully’s embeddable value data generators and data templates enable our customers to easily create intelligent fuzzers based on the expected request payload shape while controlling the generated data to test different branches of the code. This feature is available under all plans (including free plan).
The below short demo shows how easy it is to add random data to your requests.
Top API fuzzing tools
KITERUNNER
Website: github.com/assetnote/kiterunner | Price: Free and Open source
A content discovery tool that uses many open API’s specifications as a searching source to find unlinked files or folders. Also, it integrates with apps like Burp to replay the test with different permutations of the original request.
RESTRler
Website: github.com/microsoft/restler-fuzzer | Price: Free and Open source
It is the world’s first stateful API fuzzer, a Microsoft product that gets the open APIs specification and generates the tests automatically to find the vulnerability of an API.
Fuzz testing glossary
| Term | Definition |
|---|---|
| Fuzz | The random input for fuzz testing |
| Fuzzer | A program or programming code that generates random input |
| Dumb fuzzer | A fuzzer that does not know the expected input structure |
| Smart fuzzer | A fuzzer that knows input structure |
| Mutation-based fuzzer | A fuzzer that generates input by changing the provided valid input |
| Generation-based fuzzer | A fuzzer that generates input from scratch by analyzing the provided valid input |
| Code Coverage | The percentage of the code that is executed by running the test cases |
| Source code branch | A portion of the source code that will be executed under certain conditions |
Latest Advancements in Fuzz Testing
Software testing constantly evolves, with fuzz testing leading the way in uncovering critical vulnerabilities. Recent advancements, particularly the integration of AI, have revolutionized fuzz testing practices.
Integration of AI in Fuzz Testing
Integration of Artificial Intelligence (AI), particularly Large Language Models (LLMs), has significantly improved fuzz testing. Google, a pioneer in this field, has integrated LLMs into its OSS-Fuzz project, aiming to push the boundaries of traditional fuzz testing. The integration has shown promising results, especially in improving code coverage - a critical factor in the effectiveness of fuzz testing. For instance, in the tinyxml2 project, integrating LLM-generated fuzz targets increased code coverage from 38% to 69%, all without human intervention. This substantial improvement underscores the potential of AI in automating and enhancing the fuzz testing process, making it more efficient and far-reaching.
Fuzzing Competitions and their Impact
The field of fuzz testing is becoming increasingly competitive, with platforms such as Google’s FuzzBench leading the charge. These platforms organize competitions where different fuzzing tools are pitted against each other and are evaluated based on their code coverage and bug discovery capabilities. These competitive analyses are not merely academic exercises; they ensure fuzz testing methodologies and tools are robust and efficient and handle modern software complexities.
Expanding the Scope of Fuzz Testing
Fuzzing in Memory-Safe Languages
The expansion of fuzz testing into memory-safe languages, such as Rust, is a significant shift from the traditional focus on languages prone to memory safety issues. Google’s commitment to fuzzing in Rust, despite it being a memory-safe language, has led to the discovery and remediation of numerous non-security issues, thereby enhancing the stability of systems. The following points highlight the importance of fuzz testing in memory-safe languages:
- Even in memory-safe languages, fuzz testing helps uncover non-security-related issues.
- Fuzz testing contributes to the overall system stability by identifying and addressing these issues.
- The expansion into memory-safe languages demonstrates the versatility and essential role of fuzz testing in modern software development.
Conclusion
Fuzz testing is an important part of modern software testing. We find bugs and issues by giving applications random inputs. Whether using a simple dumb fuzzer or a more advanced smart fuzzer, the goal is to challenge the software and find out its weaknesses.
If you’re involved in software development or security, it’s worth diving deeper into fuzz testing and seeing how it can strengthen your projects.
Got any thoughts or questions? Feel free to share them in the comments.
Frequently Asked Questions
We got an answer for your questions
-
What exactly is fuzz testing?
Fuzz testing is a software testing technique where random data (the fuzz) is input into a program to find issues like crashes or failures. It's like testing the program's endurance by throwing unexpected scenarios.
-
What's the difference between dumb and smart fuzzers?
Dumb fuzzers don't know what the program expects and send random data. Smart fuzzers, however, are more informed and send data that's more likely to navigate through the program's logic, uncovering more complex issues.
-
Why is fuzz testing necessary?
Fuzz testing helps find bugs that other testing methods might miss, especially those that could lead to crashes or security breaches. It's like a stress test for your program to ensure it can handle unexpected inputs gracefully.
-
Can fuzz testing be automated?
Yes, fuzz testing is typically automated. You set up a fuzzer, which runs through loads of random inputs on its own, recording any issues it finds for you to fix later.
-
What advancements have been made in fuzz testing?
AI has been a game-changer in fuzz testing, making it more intelligent and efficient. For example, AI can help improve how well a fuzzer understands a program, leading to better test coverage and more bugs found.